
Data and thoughts on public and private school funding in the U.S.
Understand your data & use it wisely! Tips for avoiding stupid mistakes with publicly available NJ data
Posted on April 11, 2014
0
My next few blog posts will return to a common theme on this blog – appropriate use of publicly available data sources. I figure it’s time to put some positive, instructive stuff out there. Some guidance for more casual users (and more reckless ones) of public data sources and for those must making their way into the game. In this post, I provide a few tips on using publicly available New Jersey schools data. The guidance provided herein is largely in response to repeated errors I’ve seen over time in using and reporting New Jersey school data, where some of those errors are simple oversight and lack of deep understanding of the data, and others of those errors seem a bit more suspect. Most of these recommendations apply to using other state’s data as well. Notably, most of these are tips that a thoughtful data analyst would arrive at on his/her own, by engaging in the appropriate preliminary evaluations of the data. But sadly these days, it doesn’t seem to work that way.
So, here are a few NJ state data tips.
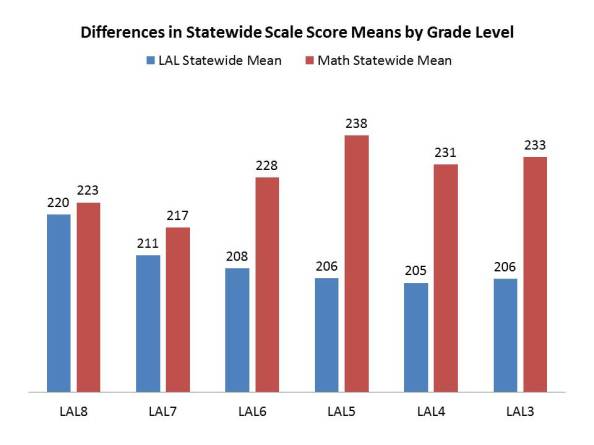
NJ ASK scale score data vary by grade level, so aggregating across grade levels produces biased comparisons if schools have different numbers of kids in different grade levels
NJ, like other states has adopted math and reading assessments from grades 3 to 8 and like other states has made numerous rather arbitrary decisions over time as to how to establish cut scores determining proficiency on the assessments, and methods for converting raw scores (numbers of items on a 50 point test) into scale scores (with proficiency cut-score of 200 and max score of 300). [1] The presumption behind this method is that “proficiency” has some common meaning across grade levels. That a child who is proficient in grade 3 math for example, if he or she learns what they are supposed to in 4th grade (and only what they are supposed to), they will again be proficient at the end of the year. But that doesn’t mean that the distributions of testing data